Examples of ours (including joint)
Work
Continued development
Peer-reviewed publications and preprints

Preprint
An in silico drug repurposing pipeline to identify drugs with the potential to inhibit SARS-CoV-2 replication
DOI: https://doi.org/10.1016/j.imu.2023.101387
Authors:
- Méabh MacMahon (a b l)
- Woochang Hwang (a l)
- Soorin Yim (c)
- Eoghan MacMahon (d)
- Alexandre Abraham (e)
- Justin Barton (f)
- Mukunthan Tharmakulasingam (g)
- Paul Bilokon (h i j)
- Vasanthi Priyadarshini Gaddi (k)
- Namshik Han (a l)
Affiliations:
- a: Milner Therapeutics Institute, University of Cambridge, Cambridge, UK
- b: Centre for Therapeutics Discovery, LifeArc, Stevenage, UK
- c: Department of Bio and Brain Engineering, KAIST, Daejeon, Republic of Korea
- d: UCD School of Chemistry, University College Dublin, Dublin, Ireland
- e: Implicity, Paris, France
- f: Institute of Structural and Molecular Biology, Birkbeck, University of London, London, UK
- g: Centre for Vision, Speech and Signal Processing, University of Surrey, Guildford, UK
- h: Department of Computing, Imperial College London, London, UK
- i: Department of Mathematics, Imperial College London, London, UK
- j: Thalesians Ltd, London, UK
- k: Centre for Genetics and Genomics Versus Arthritis, Division of Musculoskeletal and Dermatological Sciences, School of Biological Sciences, Faculty of Biology, Medicine and Health, The University of Manchester, Manchester, UK
- l: Cambridge Centre for AI in Medicine, Department of Applied Mathematics and Theoretical Physics, University of Cambridge, Cambridge, UK
Journal: Informatics in Medicine Unlocked
Date: October 21, 2023
Abstract:
Background
Drug repurposing provides an opportunity to redeploy drugs, which are already tested for safety or approved for use in humans, for the treatment of diseases distinct from their primary indication. For example, the repurposing of dexamethasone and baricitinib has played a crucial role in saving patient lives during the SARS-CoV-2 pandemic. There remains a need to expand therapeutic approaches to prevent life-threatening complications in vulnerable patients with COVID-19.
Method
Using an in silico approach based on structural similarity to drugs already in clinical trials for COVID-19, potential drugs were predicted for repurposing. For a subset of identified drugs with different targets to their corresponding COVID-19 clinical trial drug, a mechanism of action analysis based on affected pathways in the context of the first 24 h of infection was applied to establish whether they might have a role in inhibiting the replication of SARS-CoV-2.
Results
Twenty-nine structurally similar drugs with potential for repurposing against COVID-19 were predicted. Two of these with the potential to inhibit SARS-CoV-2 replication were identified using mechanism of action analysis. Triamcinolone is a corticosteroid that is structurally similar to dexamethasone; gallopamil is a calcium channel blocker that is structurally similar to verapamil.
Conclusion
The identification of these drugs as potentially useful for patients with COVID-19 who are at a higher risk of developing severe disease supports the use of in silico approaches to facilitate quick and cost-effective identification of drugs for repurposing. Such drugs could expand the number of treatments available to the subset of patients who are not fully protected by vaccination.
Preprint: https://arxiv.org/abs/2107.02905
Preprint
Combining Deep Learning on Order Books with Reinforcement Learning for Profitable Trading
Authors: Koti Jaddu and Paul Bilokon
Journal: SSRN
Date: October 24, 2023
High-frequency trading is prevalent, where automated decisions must be made quickly to take advantage of price imbalances and patterns in price action that forecast near-future movements. While many algorithms have been explored and tested, analytical methods fail to harness the whole nature of the market environment by focusing on a limited domain. With the evergrowing machine learning field, many large-scale end-to-end studies on raw data have been successfully employed to increase the domain scope for profitable trading but are very difficult to replicate. Combining deep learning on the order books with reinforcement learning is one way of breaking down large-scale end-to-end learning into more manageable and lightweight components for reproducibility, suitable for retail trading.
The following work focuses on forecasting returns across multiple horizons using order flow imbalance and training three temporal-difference learning models for five financial instruments to provide trading signals. The instruments used are two foreign exchange pairs (GBPUSD and EURUSD), two indices (DE40 and FTSE100), and one commodity (XAUUSD). The performances of these 15 agents are evaluated through backtesting simulation, and successful models proceed through to forward testing on a retail trading platform. The results prove potential but require further minimal modifications for consistently profitable trading to fully handle retail trading costs, slippage, and spread fluctuation.

Preprint
Implementing Portfolio Risk Management and Hedging in Practice
Authors: Paul Bilokon
Journal: SSRN
Date: 25 October 2023
In academic literature portfolio risk management and hedging are often versed in the language of stochastic control and Hamilton-Jacobi-Bellman (HJB) equations in continuous time. In practice the continuous-time framework of stochastic control may be undesirable for various business reasons. In this work we present a straightforward approach for thinking of cross-asset portfolio risk management and hedging, providing some implementation details, while rarely venturing outside the convex optimisation setting of (approximate) quadratic programming (QP). We pay particular attention to the correspondence between the economic concepts and their mathematical representations; the abstractions enabling us to handle multiple asset classes and risk models at once; the dimensional analysis of the resulting equations; and the assumptions inherent in our derivations. We demonstrate how to solve the resulting QPs with CVXOPT.
Preprint
Transformers Versus LSTMs for Electronic Trading
Authors: Paul Bilokon and Yitao Qiu
Journal: SSRN
Date: 17 October 2023
With the rapid development of artificial intelligence, long short term memory (LSTM), one kind of recurrent neural network (RNN), has been widely applied in time series prediction.
Like RNN, Transformer is designed to handle the sequential data. As Transformer achieved great success in Natural Language Processing (NLP), researchers got interested in Transformer’s performance on time series prediction, and plenty of Transformer-based solutions on long time series forecasting have come out recently. However, when it comes to financial time series prediction, LSTM is still a dominant architecture. Therefore, the question this study wants to answer is: whether the Transformer-based model can be applied in financial time series prediction and beat LSTM.
To answer this question, various LSTM-based and Transformer-based models are compared on multiple financial prediction tasks based on high-frequency limit order book data. A new LSTM-based model called DLSTM is built and new architecture for the Transformer-based model is designed to adapt for financial prediction. The experiment result reflects that the Transformer-based model only has the limited advantage in absolute price sequence prediction. The LSTM-based models show better and more robust performance on difference sequence prediction, such as price difference and price movement.
Preprint
Applying Deep Learning to Calibrate Stochastic Volatility Models
Authors: Abir Sridi and Paul Bilokon
Journal: SSRN
Date: 16 October 2023
Stochastic volatility models, where the volatility is a stochastic process, can capture most of the essential stylized facts of implied volatility surfaces and give more realistic dynamics of the volatility smile or skew. However, they come with the significant issue that they take too long to calibrate.
Alternative calibration methods based on Deep Learning (DL) techniques have been recently used to build fast and accurate solutions to the calibration problem. Huge and Savine developed a Differential Deep Learning (DDL) approach, where Machine Learning models are trained on samples of not only features and labels but also differentials of labels to features. The present work aims to apply the DDL technique to price vanilla European options (i.e. the calibration instruments), more specifically, puts when the underlying asset follows a Heston model and then calibrate the model on the trained network. DDL allows for fast training and accurate pricing. The trained neural network dramatically reduces Heston calibration’s computation time.
In this work, we also introduce different regularisation techniques, and we apply them notably in the case of the DDL. We compare their performance in reducing overfitting and improving the generalisation error. The DDL performance is also compared to the classical DL (without differentiation) one in the case of Feed-Forward Neural Networks. We show that the DDL outperforms the DL.

Preprint
Derivatives Sensitivities Computation under Heston Model on GPU
Authors: Pierre-Antoine Arsaguet and Paul Bilokon
Journal: SSRN
Date: 13 October 2023
This work investigates the computation of option Greeks for European and Asian options under the Heston stochastic volatility model on GPU. We first implemented the exact simulation method proposed by Broadie and Kaya and used it as a baseline for precision and speed. We then proposed a novel method for computing Greeks using the Milstein discretisation method on GPU. Our results show that the proposed method provides a speed-up up to 200x compared to the exact simulation implementation and that it can be used for both European and Asian options. However, the accuracy of the GPU method for estimating Rho is inferior to the CPU method. Overall, our study demonstrates the potential of GPU for computing derivatives sensitivies with numerical methods.
Preprint
Real-time VaR Calculations for Crypto Derivatives in Kdb+/q
Authors: Yutong Chen, Paul Bilokon, Conan Hales, and Laura Kerr
Journal: SSRN
Date: 3 October 2023
Cryptocurrency market is known for exhibiting significantly higher volatility than traditional asset classes. Efficient and adequate risk calculation is vital for managing risk exposures in such market environments where extreme price fluctuations occur in short timeframes. The objective of this thesis is to build a real-time computation workflow that provides VaR estimates for non-linear portfolios of cryptocurrency derivatives. Many researchers have examined the predictive capabilities of time-series models within the context of cryptocurrencies. In this work, we applied three commonly used models – EMWA, GARCH and HAR – to capture and forecast volatility dynamics, in conjunction with delta-gamma-theta approach and Cornish-Fisher expansion to crypto derivatives, examining their performance from the perspectives of calculation efficiency and accuracy. We present a calculation workflow which harnesses the information embedded in high-frequency market data and the computation simplicity inherent in analytical estimation procedures. This workflow yields reasonably robust VaR estimates with calculation latencies on the order of milliseconds.
Preprint
From Deep Filtering to Deep Econometrics
Authors: Robert Stok and Paul Bilokon
Journal: SSRN
Date: 2 October 2023
Calculating true volatility is an essential task for option pricing and risk management. However, it is made difficult by market microstructure noise. Particle filtering has been proposed to solve this problem as it favorable statistical properties, but relies on assumptions about underlying market dynamics. Machine learning methods have also been proposed but lack interpretability, and often lag in performance. In this paper we implement the SV-PF-RNN: a hybrid neural network and particle filter architecture. Our SV-PF-RNN is designed specifically with stochastic volatility estimation in mind. We then show that it can improve on the performance of a basic particle filter.

Preprint
A Compendium of Data Sources for Data Science, Machine Learning, and Artificial Intelligence
Authors: Paul Bilokon, Oleksandr Bilokon, and Saeed Amen
Journal: SSRN
Date: 12 September 2023
Recent advances in data science, machine learning, and artificial intelligence, such as the emergence of large language models, are leading to an increasing demand for data that can be processed by such models. While data sources are application-specific, and it is impossible to produce an exhaustive list of such data sources, it seems that a comprehensive, rather than complete, list would still benefit data scientists and machine learning experts of all levels of seniority. The goal of this publication is to provide just such an (inevitably incomplete) list – or compendium – of data sources across multiple areas of applications, including finance and economics, legal (laws and regulations), life sciences (medicine and drug discovery), news sentiment and social media, retail and ecommerce, satellite imagery, and shipping and logistics, and sports.
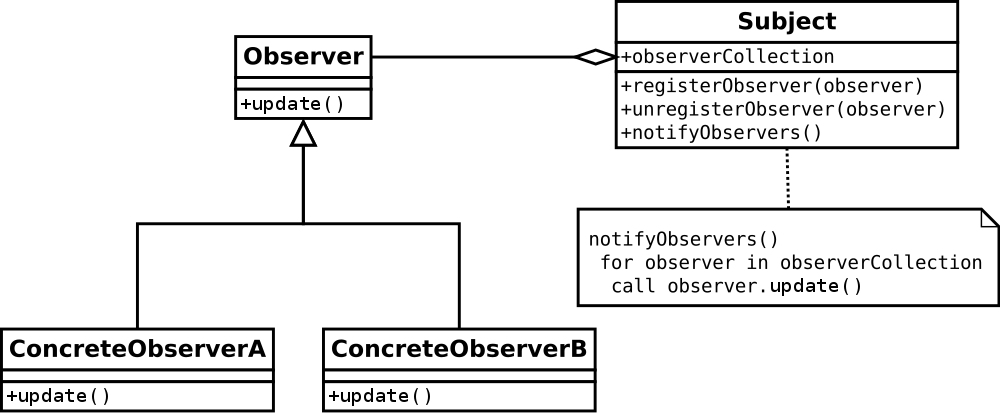
Preprint
C++ Design Patterns for Low-Latency Applications Including High-Frequency Trading
Authors: Paul Bilokon and Burak Gunduz
Journal: SSRN
Date: 9 September 2023
This work aims to bridge the existing knowledge gap in the optimisation of latency-critical code, specifically focusing on high-frequency trading (HFT) systems. The research culminates in three main contributions: the creation of a Low-Latency Programming Repository, the optimisation of a market-neutral statistical arbitrage pairs trading strategy, and the implementation of the Disruptor pattern in C++. The repository serves as a practical guide and is enriched with rigorous statistical benchmarking, while the trading strategy optimisation led to substantial improvements in speed and profitability. The Disruptor pattern showcased significant performance enhancement over traditional queuing methods. Evaluation metrics include speed, cache utilisation, and statistical significance, among others. Techniques like Cache Warming and Constexpr showed the most significant gains in latency reduction. Future directions involve expanding the repository, testing the optimised trading algorithm in a live trading environment, and integrating the Disruptor pattern with the trading algorithm for comprehensive system benchmarking. The work is oriented towards academics and industry practitioners seeking to improve performance in latency-sensitive applications.
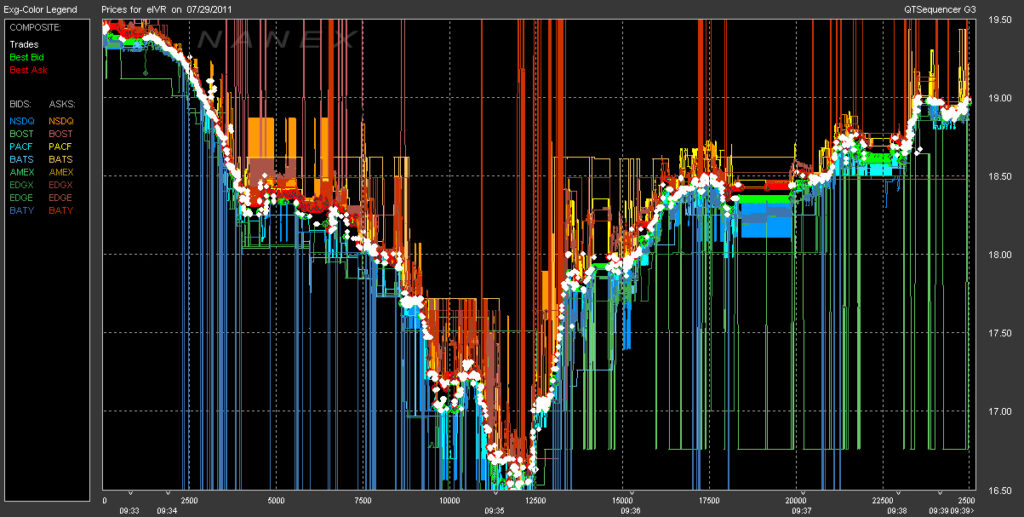
Preprint
Semi-static Conditions in Low-latency C++ for High Frequency Trading: Better than Branch Prediction Hints
Authors: Paul Bilokon, Maximilian Lucuta, and Erez Shermer
Journal: SSRN
Date: 28 August, 2023
Conditional branches pose a challenge for code optimisation, particularly in low latency settings. For better performance, processors leverage dedicated hardware to predict the outcome of a branch and execute the following instructions speculatively, a powerful optimisation. Modern branch predictors employ sophisticated algorithms and heuristics that utilise historical data and patterns to make predictions, and often, are extremely effective at doing so. Consequently, programmers may inadvertently underestimate the cost of misprediction when benchmarking code with synthetic data that is either too short or too predictable. While eliminating branches may not always be feasible, C++20 introduced the [[likely]] and [[unlikely]] attributes that enable the compiler to perform spot optimisations on assembly code associated with likely execution paths. Can we do better than this?
This work presents the development of a novel language construct, referred to as a semi-static condition, which enables programmers to dynamically modify the direction of a branch at run-time by modifying the assembly code within the underlying executable. Subsequently, we explore scenarios where the use of semi-static conditions outperforms traditional conditional branching, highlighting their potential applications in real-time machine learning and high-frequency trading. Throughout the development process, key considerations of performance, portability, syntax, and security were taken into account.
Preprint
Exploring the Advantages of Transformers for High-Frequency Trading
Authors: Fazl Barez, Paul Bilokon, Arthur Gervais, and Nikita Lisitsyn
Journal: SSRN
Date: 24 February 2023
This paper explores the novel deep learning Transformers architectures for high-frequency Bitcoin-USDT log-return forecasting and compares them to the traditional Long Short-Term Memory models. A hybrid Transformer model, called HFformer, is then introduced for time series forecasting which incorporates a Transformer encoder, linear decoder, spiking activations, and quantile loss function, and does not use position encoding. Furthermore, possible high-frequency trading strategies for use with the HFformer model are discussed, including trade sizing, trading signal aggregation, and minimal trading threshold. Ultimately, the performance of the HFformer and Long Short-Term Memory models are assessed and results indicate that the HFformer achieves a higher cumulative PnL than the LSTM when trading with multiple signals during backtesting.

Preprint
Benchmarking Specialized Databases for High-frequency Data
Authors: Fazl Barez, Paul Bilokon, and Ruijie Xiong
Journal: SSRN
Date: 31 January 2023
This paper presents a benchmarking suite designed for the evaluation and comparison of time series databases for high-frequency data, with a focus on financial applications. The proposed suite comprises of four specialized databases: ClickHouse, InfluxDB, kdb+ and TimescaleDB. The results from the suite demonstrate that kdb+ has the highest performance amongst the tested databases, while also highlighting the strengths and weaknesses of each of the databases. The benchmarking suite was designed to provide an objective measure of the performance of these databases as well as to compare their capabilities for different types of data. This provides valuable insights into the suitability of different time series databases for different use cases and provides benchmarks that can be used to inform system design decisions.
Peer-reviewed publication
Quasi-Monte Carlo Methods for Calculating Derivatives Sensitivities on the GPU
Authors: Paul Bilokon, Sergei Kucherenko, and Casey Williams
Journal: SSRN
Date: 28 September 2022
The calculation of option Greeks is vital for risk management. Traditional pathwise and finite-difference methods work poorly for higher-order Greeks and options with discontinuous payoff functions. The Quasi-Monte Carlo-based conditional pathwise method (QMC-CPW) for options Greeks allows the payoff function of options to be effectively smoothed, allowing for increased efficiency when calculating sensitivities. Also demonstrated in literature is the increased computational speed gained by applying GPUs to highly parallelisable finance problems such as calculating Greeks. We pair QMC-CPW with simulation on the GPU using the CUDA platform. We estimate the delta, vega and gamma Greeks of three exotic options: arithmetic Asian, binary Asian, and lookback. Not only are the benefits of QMC-CPW shown through variance reduction factors of up to $1.0 \times 10^{18}$, but the increased computational speed through usage of the GPU is shown as we achieve speedups over sequential CPU implementations of more than $200$x for our most accurate method.
Preprint: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4227386
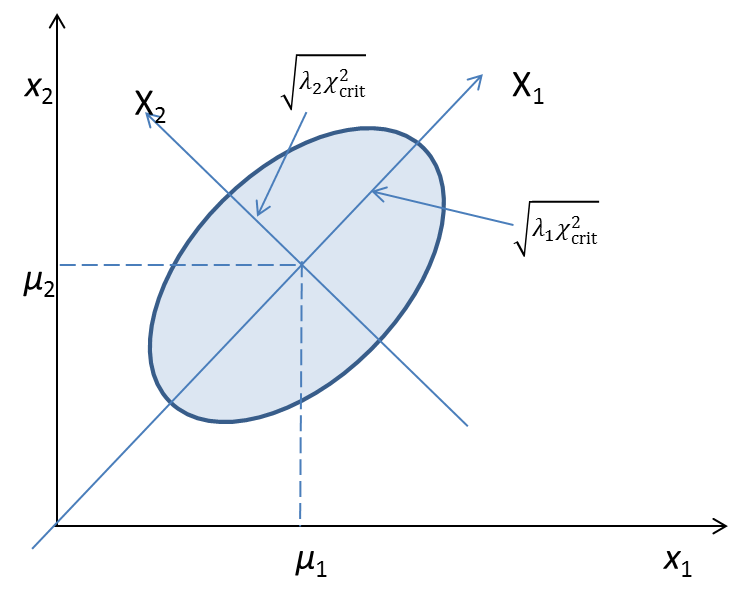
Preprint
Iterated and Exponentially Weighted Moving Principal Component Analysis
Authors: Paul Bilokon and David Finkelstein
Journal: SSRN
Date: 1 September 2021
The principal component analysis (PCA) is a staple statistical and unsupervised machine learning technique in finance. The application of PCA in a financial setting is associated with several difficulties, such as numerical instability and nonstationarity. We attempt to resolve them by proposing two new variants of PCA: an iterated principal component analysis (IPCA) and an exponentially weighted moving principal component analysis (EWMPCA). Both variants rely on the Ogita-Aishima iteration as a crucial step.
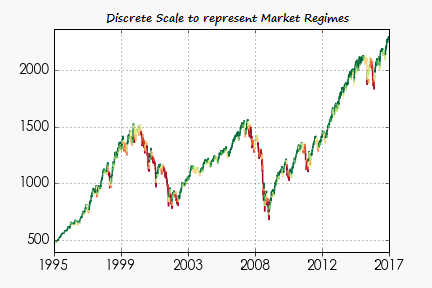
Preprint
Market Regime Classification with Signatures
Authors: Antoine (Jack) Jacquier, Paul Bilokon, and Conor McIndoe
Journal: SSRN
Date: 8 July 2021
We provide a data-driven algorithm to classify market regimes for time series.
We utilise the path signature, encoding time series into easy-to-describe objects, and provide a metric structure which establishes a connection between separation of regimes and clustering of points.
Dissertation
Bayesian methods for solving estimation and forecasting problems in the high-frequency trading environment
Authors: Paul Bilokon
Institution: Christ Church college, the University of Oxford
Date: 16 December 2016
We examine modern stochastic filtering and Markov chain Monte Carlo (MCMC) methods and consider their applications in finance, especially electronic trading.
Stochastic filtering methods have found many applications, from Space Shuttles to self-driving cars. We review some classical and modern algorithms and show how they can be used to estimate and forecast econometric models, stochastic volatility and term structure of risky bonds. We discuss the practicalities, such as outlier filtering, parameter estimation, and diagnostics.
We focus on one particular application, stochastic volatility with leverage, and show how recent advances in filtering methods can help in this application: kernel density estimation can be used to estimate the predicted observation, filter out outliers, detect structural change, and improve the root mean square error while preventing discontinuities due to the resampling step.
We then take a closer look at the discretisation of the continuous-time stochastic volatility models and show how an alternative discretisation, based on what we call a filtering Euler–Maruyama scheme, together with our generalisation of Gaussian assumed density filters to arbitrary (not necessarily additive) correlated process and observation noises, gives rise to a new, very fast approximate filter for stochastic volatility with leverage. Its accuracy falls short of particle filters but beats the unscented Kalman filter. Due to its speed and reliance exclusively on scalar computations this filter will be particularly useful in a high-frequency trading environment.
In the final chapter we examine the leverage effect in high-frequency trade data, using last data point interpolation, tick and wall-clock time and generalise the models to take into account the time intervals between the ticks.
We use a combination of MCMC methods and particle filtering methods. The robustness of the latter helps estimate parameters and compute Bayes factors. The speed and precision of modern filtering algorithms enables real-time filtering and prediction of the state.

Peer-reviewed publication
A domain-theoretic approach to Brownian motion and general continuous stochastic processes
Authors: Paul Bilokon and Abbas Edalat
Journal: Theoretical Computer Science, Volume 691
Date: August 2017
We introduce a domain-theoretic framework for continuous-time, continuous-state stochastic processes. The laws of stochastic processes are embedded into the space of maximal elements of the normalised probabilistic power domain on the space of continuous interval-valued functions endowed with the relative Scott topology. We use the resulting omega-continuous bounded complete dcpo to define partial stochastic processes and characterise their computability. For a given continuous stochastic process, we show how its domain-theoretic, i.e., finitary, approximations can be constructed, whose least upper bound is the law of the stochastic process. As a main result, we apply our methodology to Brownian motion. We construct a partial Wiener measure and show that the Wiener measure is computable within the domain-theoretic framework.
Peer-reviewed publication
A domain-theoretic approach to Brownian motion and general continuous stochastic processes
DOI: https://doi.org/10.1145/2603088.2603102
Authors: Paul Bilokon and Abbas Edalat
Journal: CSL-LICS ’14: Proceedings of the Joint Meeting of the Twenty-Third EACSL Annual Conference on Computer Science Logic (CSL) and the Twenty-Ninth Annual ACM/IEEE Symposium on Logic in Computer Science (LICS), July 2014, Article No.: 15, Pages 1–10
Date: 28 August, 2023
We introduce a domain-theoretic framework for continuous-time, continuous-state stochastic processes. The laws of stochastic processes are embedded into the space of maximal elements of the normalised probabilistic power domain on the space of continuous interval-valued functions endowed with the relative Scott topology. We use the resulting omega-continuous bounded complete dcpo to define partial stochastic processes and characterise their computability. For a given continuous stochastic process, we show how its domain-theoretic, i.e., finitary, approximations can be constructed, whose least upper bound is the law of the stochastic process. As a main result, we apply our methodology to Brownian motion. We construct a partial Wiener measure and show that the Wiener measure is computable within the domain-theoretic framework.

Dissertation
Visualising the Invisible: Detecting Objects in Quantum Noise Limited Images
Authors: Paul Bilokon
Institution: Imperial College London
Date: June 2005
Abstract:
Single particle electron microscopy has over the last decade emerged as an important new technique in structural biology for determining the three-dimensional structures of biological macromolecules. The critical step in the process is to find the molecules in the digitised electron micrographs.
The electron illumination used to collect the images of the particles is, at the same time, very damaging to the biological molecules and we thus need to collect the data at as low an electron exposure as possible. The problem is that beyond some point we no longer can see the particles in the images that can best be described as an ocean of quantum noise.
Modern particle recognition algorithms can approach the detection capacity of the human visual system. Computational detection of the particles has the advantage of being able to chew through terabytes of image information without the operator getting tired or without the danger of introducing too much bias into the data set.
A detailed survey of the current state-of-the-art in automated particle selection is performed and the most promising methods, algorithms, and implementations are compared and contrasted. It is shown that a truly flexible, extensible, visual solution could aid the creation of new particle picking algorithms.
As a consequence of this research, a new image processing system is developed, whose functionality extends far beyond automated particle selection. This application, called Horus, is the first workflow-based image processing system in electron microscopy, which can be used for particle selection.
Books

Book
The Book of Alternative Data: A Guide for Investors, Traders, and Risk Managers
Authors: Alexander Denev and Saeed Amen
Publisher: Wiley
Year: 2020
The first and only book to systematically address methodologies and processes of leveraging non-traditional information sources in the context of investing and risk management
Harnessing non-traditional data sources to generate alpha, analyze markets, and forecast risk is a subject of intense interest for financial professionals. A growing number of regularly-held conferences on alternative data are being established, complemented by an upsurge in new papers on the subject. Alternative data is starting to be steadily incorporated by conventional institutional investors and risk managers throughout the financial world. Methodologies to analyze and extract value from alternative data, guidance on how to source data and integrate data flows within existing systems is currently not treated in literature. Filling this significant gap in knowledge, The Book of Alternative Data is the first and only book to offer a coherent, systematic treatment of the subject.
This groundbreaking volume provides readers with a roadmap for navigating the complexities of an array of alternative data sources, and delivers the appropriate techniques to analyze them. The authors—leading experts in financial modeling, machine learning, and quantitative research and analytics—employ a step-by-step approach to guide readers through the dense jungle of generated data. A first-of-its kind treatment of alternative data types, sources, and methodologies, this innovative book:
- Provides an integrated modeling approach to extract value from multiple types of datasets
- Treats the processes needed to make alternative data signals operational
- Helps investors and risk managers rethink how they engage with alternative datasets
- Features practical use case studies in many different financial markets and real-world techniques
- Describes how to avoid potential pitfalls and missteps in starting the alternative data journey
- Explains how to integrate information from different datasets to maximize informational value
The Book of Alternative Data is an indispensable resource for anyone wishing to analyze or monetize different non-traditional datasets, including Chief Investment Officers, Chief Risk Officers, risk professionals, investment professionals, traders, economists, and machine learning developers and users.
Book
Machine Learning in Finance: From Theory to Practice
Authors: Matthew Dixon, Igor Halperin, and Paul Bilokon
Publisher: Springer
Year: 2020
This book introduces machine learning methods in finance. It presents a unified treatment of machine learning and various statistical and computational disciplines in quantitative finance, such as financial econometrics and discrete time stochastic control, with an emphasis on how theory and hypothesis tests inform the choice of algorithm for financial data modeling and decision making. With the trend towards increasing computational resources and larger datasets, machine learning has grown into an important skillset for the finance industry. This book is written for advanced graduate students and academics in financial econometrics, mathematical finance and applied statistics, in addition to quants and data scientists in the field of quantitative finance.
Machine Learning in Finance: From Theory to Practice is divided into three parts, each part covering theory and applications. The first presents supervised learning for cross-sectional data from both a Bayesian and frequentist perspective. The more advanced material places a firm emphasis on neural networks, including deep learning, as well as Gaussian processes, with examples in investment management and derivative modeling. The second part presents supervised learning for time series data, arguably the most common data type used in finance with examples in trading, stochastic volatility and fixed income modeling. Finally, the third part presents reinforcement learning and its applications in trading, investment and wealth management. Python code examples are provided to support the readers’ understanding of the methodologies and applications. The book also includes more than 80 mathematical and programming exercises, with worked solutions available to instructors. As a bridge to research in this emergent field, the final chapter presents the frontiers of machine learning in finance from a researcher’s perspective, highlighting how many well-known concepts in statistical physics are likely to emerge as important methodologies for machine learning in finance.


Book
Machine Learning and Big Data with kdb+/q
Authors: Jan Novotny, Paul Bilokon, Aris Galiotos, and Frédéric Délèze
Publisher: Wiley
Year: 2019
Upgrade your programming language to more effectively handle high-frequency data.
Machine Learning and Big Data with KDB+/Q offers quants, programmers and algorithmic traders a practical entry into the powerful but non-intuitive kdb+ database and q programming language. Ideally designed to handle the speed and volume of high-frequency financial data at sell- and buy-side institutions, these tools have become the de facto standard; this book provides the foundational knowledge practitioners need to work effectively with this rapidly-evolving approach to analytical trading.
The discussion follows the natural progression of working strategy development to allow hands-on learning in a familiar sphere, illustrating the contrast of efficiency and capability between the q language and other programming approaches. Rather than an all-encompassing “bible”-type reference, this book is designed with a focus on real-world practicality to help you quickly get up to speed and become productive with the language.
- Understand why kdb+/q is the ideal solution for high-frequency data
- Delve into “meat” of q programming to solve practical economic problems
- Perform everyday operations including basic regressions, cointegration, volatility estimation, modelling and more
- Learn advanced techniques from market impact and microstructure analyses to machine learning techniques including neural networks
The kdb+ database and its underlying programming language q offer unprecedented speed and capability. As trading algorithms and financial models grow ever more complex against the markets they seek to predict, they encompass an ever-larger swath of data – more variables, more metrics, more responsiveness and altogether more “moving parts.”
Traditional programming languages are increasingly failing to accommodate the growing speed and volume of data, and lack the necessary flexibility that cutting-edge financial modelling demands. Machine Learning and Big Data with KDB+/Q opens up the technology and flattens the learning curve to help you quickly adopt a more effective set of tools.
Book
Novel Methods in Computational FInance
Chapter: Stochastic Filtering Methods in Electronic Trading
Authors: Paul Bilokon, James Gwinnutt, and Daniel Jones
Editors: Matthias Ehrhardt, Michael Günther, E. Jan W. ter Maten
Authors: Matthew Dixon, Igor Halperin, and Paul Bilokon
Publisher: Springer
Year: 2017
This book discusses the state-of-the-art and open problems in computational finance. It presents a collection of research outcomes and reviews of the work from the STRIKE project, an FP7 Marie Curie Initial Training Network (ITN) project in which academic partners trained early-stage researchers in close cooperation with a broader range of associated partners, including from the private sector.
The aim of the project was to arrive at a deeper understanding of complex (mostly nonlinear) financial models and to develop effective and robust numerical schemes for solving linear and nonlinear problems arising from the mathematical theory of pricing financial derivatives and related financial products. This was accomplished by means of financial modelling, mathematical analysis and numerical simulations, optimal control techniques and validation of models.
In recent years the computational complexity of mathematical models employed in financial mathematics has witnessed tremendous growth. Advanced numerical techniques are now essential to the majority of present-day applications in the financial industry.
Special attention is devoted to a uniform methodology for both testing the latest achievements and simultaneously educating young PhD students. Most of the mathematical codes are linked into a novel computational finance toolbox, which is provided in MATLAB and PYTHON with an open access license. The book offers a valuable guide for researchers in computational finance and related areas, e.g. energy markets, with an interest in industrial mathematics.


Book
Trading Thalesians: What the Ancient World Can Teach Us about Trading Today
Author: Saeed Amen
Publisher: Wiley
Year: 2014
What can the ancient world teach us about modern money markets? How can we use examples from the ancient world, philosophers and writers to better understand the markets? Just as historians such as Herodotus living in ancient Greece examined the past, can traders look to their past to learn something new?
In this exciting new book, Saeed Amen looks to the ancient world to help us better understand modern money markets, demonstrating what ancient philosophers can teach us about trading markets today, and showing readers how to maximize their returns.
Based on the rationale that if your primary objective is purely to make money from trading quickly, you can make decisions that perversely increase the likelihood of losing; this book demonstrates how successful trading can actually be achieved as a byproduct of good trading.
Relating concepts from the ancient world, such as water and risk, diversified knowledge, Herodotus and historical bias to the modern world money markets, Amen demonstrates that by focusing on goals that go beyond making money, lateral thinking, targeting risk adjusted returns, and keeping drawdowns in check, investors will indirectly make more money in the long run.
Investors might be fooled by randomness on occasion, but luck can never be derided as an important factor, which helps investors succeed. Instead repeated success in investing capital over an extended period seems to be less a product of randomness, but instead a product of a profound understanding of markets.
Software Libraries

Software library
quantQ
As part of the Machine Learning and Big Data with kdb+/q book project authored by Jan Novotny, Paul Bilokon, Aris Galiotos, and Frédéric Délèze, we have contributed to the quantQ library—a project managed my Jan Novotny (hanssmail on GitHub).
The library has since been extended beyond the book and implements:
- mathematical functions
- biostatistics
- optimization
- bioinformatics
- dynamic time warp
- deep neural networks
- stochastic optimization
- support vector machines
- Poisson regression
Software Library
tsa: The Thalesians' Time Series Analysis Library (TSA)
Installation: pip install thalesians.tsa
The Thalesians time series library is a heterogeneous collection of tools for facilitating efficient
- data analysis and, more broadly,
- data science; and
- machine learning.
The originating developes’ primary applications are
- quantitative finance and economics;
- electronic trading, especially,
- algorithmic trading, especially,
- algorithmic market making;
- high-frequency finance;
- financial alpha generation;
- client analysis;
- risk analysis;
- financial strategy backtesting.
However, since data science and machine learning are universal, it is hoped that this code will be useful in other areas. Therefore we are looking for contributors with the above backgrounds as well as
- computer science,
- engineering, especially mechanical, electrical, electronic, marine, aeronautical, and aerospace,
- science, especially biochemistry and genetics, and
- medicine.
Currently, the following functionality is implemented and is being expanded:
- stochastic filtering, including Kalman and particle filtering approaches,
- stochastic processes, including mean-reverting (Ornstein-Uhlenbeck) processes,
- Gauss-Markov processes,
- stochastic simulation, including Euler-Maruyama scheme,
- interprocess communication via “pypes”,
- online statistics,
- visualisation, including interactive visualisation for Jupyter,
- pre-, post-condition, and invariant checking,
- utilities for dealing with Pandas dataframes, especially large ones,
- native Python, NumPy, and Pandas type conversions,
- interoperability with kdb+/q.


Software library
nanotemporals
Nanosecond-precision temporal types for Java.
In modern-day neocybernetics applications, such as high-frequency electronic/algorithmic trading, high-frequency time series econometrics, robotics, and others, timestamps of necessity have nanosecond precision.
This library implements nanosecond-precision temporal types for such applications.
We would like to thank all those former and current colleagues from whom we have learned so much about Java programming.
We welcome requests for collaboration on maintaining this library and taking it further.
Comments, bug fixes, and new ideas are most welcome.
Software Library
LaThalesians
The LaThalesians library comprises a heterogeneous collection of LaTeX packages, which facilitate the type-setting of the Thalesians’ work in mathematics, computer science, and finance. It was originally developed by Paul Bilokon to support his academic and professional work and the library’s scope still reflects some of his personal biases, viz.:
- mathematical finance,
- econometrics,
- programming,
- scientific computing,
- algorithms,
- statistics,
- stochastic analysis,
- probability theory,
- domain theory,
- computability theory.
It is hoped that, as more people get involved in the development and maintenance of this library, its scope will become more balanced and will more faithfully reflect the diverse activities of the Thalesians.
Rather than being structured as a single package, LaThalesians is a suite of packages, each package name starting with lathalesians-. Thus the modules may be used individually, depending on the user’s specific needs. Modularity is one of the design principles that guided us in this library’s development.
Another one is simplicity: tasks that occur often in our research and development work should be made easy. The syntax should be straightforward and easy to remember. LaTeX commands that we type in often should be brief.
But not too brief: they should still be unambiguous and easy to remember. Readability and clarity are also important to us. Finding the right balance between simplicity and readability is an art more than a science.
We are believers in domain-specific languages. Therefore we often define LaTeX commands to represent the concepts from a particular research area rather than typesetting instructions. This is done at the cost of introducing more words into our language. We believe that these are the very words that we need. Let’s express what things are, rather than what they should look like.
Finally, we believe that truth and beauty should go hand in hand. Both should be present in the content. Form should do justice to the content’s truth and present it in a way that is beautiful. We don’t claim that we have achieved this in LaThalesians. However, this is indeed our striving, our intention. We will be very much obliged for any recommendations on how to make the library’s output more aesthetically pleasing.
We, the Thalesians, would be very much obliged to you for your contributions to this library. It is far from perfect now. In many ways it is quite defective. Please help us make it both useful and beautiful.

Papers and preprints
0
Books
0
Software libraries
0