Customer-centred
Consulting
Leading together
Consulting
Services
We consult some of the leading organizations across many industries on different aspects of modern science and technology.
Our experts work alongside their clients on site or from our offices in Canary Wharf.
Whatever the challenge, we offer a thorough analysis of the task at hand, engage the client throughout all stages of development, and produce thorough, comprehensive, state-of-the-art solutions to meet the clients’ needs.

Neocybernetics

Neocybernetics
Current progress
- Early 1940s: early computers
- Late 1940s: cybernetics
- Early 1950s: computational statistics
- Mid 1950s: machine learning
- 1956: artificial intelligence (AI)
- Mid 1960s: natural language processing (NLP)
- Late 1960s: computer vision
- Late 1970s: robotics
- 1990s–2000s: data science and data mining
- 2010s: deep learning
- 2020s: neocybernetics
In 1956, Herb Simon, one of the "fathers of artificial intelligence", predicted that within ten years computers would beat the world chess champion, compose “aesthetically satisfying” original music, and prove new mathematical theorems. It took forty years, not ten, but all these goals were achieved – and within a few years of each other! The music composed by David Cope’s programs cannot be distinguished, even by professors of music, from that composed by Mozart, Beethoven, and Bach. In 1976, a computer was used in the proof of the long-unsolved “four colour problem”.
Michael J. Beeson. The Mechanisation of Mathematics, in "Alan Turing: Life and Legacy of a Great Thinker" (2004).

Consulting
Neocybernetics
We call the new science, built on the foundation of several modern and classical disciplines, neocybernetics. We are a neocybernetics company using the new science and technology to revolutionize finance, insurance, transportation, shipping, and medicine in the United Kingdom and worldwide.
Neocybernetics is built on:
- data science
- machine learning (ML)
- deep learning (DL)
- reinforcement learning (RL)
- deep reinforcement learning (DRL)
- artificial intelligence (AI)
- big data
- high-frequency data analysis
- markets microstructure
- quantitative finance
- electronic trading
- algorithmic trading
- real-time computing
- high-performance computing
- reactive programming
- message-driven architectures
- low-latency messaging

Neocybernetics
Time Series
Among other things, we apply neocybernetics to time series–sequences of timestamped updates, arriving in chronological order, on the state of a particular process evolving over time.
Example applications:
- stock prices
- interest rates
- currency exchange rates, including cryptocurrencies, such as bitcoin
- micro- and macroeconomic data
- states of a particular machine, e.g. in a car, on a ship, airplane, or on a space station
- electrocardiogram (ECG) tests
- electroencephalogram (EEG) tests
- at the microscopic level, metabolic chain states
- any medical test results as they evolve over time
- fitband readings
Data Science

Consulting
Data Science
Data science is the art, craft, and science of making sense of data. And not only making sense, but drawing nontrivial and practically useful conclusions, that can be (and must be!) constructively acted upon to achieve better outcomes. It is important because we desperately need those better outcomes–as a species and as individual persons.
We live in the age of data science. Whatever your business, the ability to learn more about your customers, and about your customers’ demands enables you to optimize your marketing and sales, and to provide a better offering, thus increasing your profitability.
Data science is driven by the rise in the availability and quality of data and computational resources.
You can use data science to improve patients’ outcomes, your town’s security, find gold, oil, and other commodities, optimize ship and airplane traffic, and energy consumption; you can look at the big picture and take into account the finest, nano scale. Whatever the type of your organization, you can use data science to achieve the maximum level of efficiency.
Companies such as Amazon.com, Inc.; Apple Inc.; Facebook Inc.; Google LLC; Roofoods Ltd (branded as Deliveroo); Uber Technologies, Inc. can all be thought of as data science companies because their business edge comes from their ability to collect, process, and take advantage of, data.
Artificial Intelligence / Machine Learning

Consulting
Artificial Intelligence
Artificial Intelligence (AI) was first defined by John McCarthy as “the science and engineering of making intelligent machines, especially intelligent computer programs”. The early researchers in AI set the target very high: they aimed to recreate the human intelligence.
In the 1950s and 1960s this promise failed to materialize. Perhaps because the target was not only high, but moving: the moment the machine learned to do something as well as, or better than, humans, people stopped referring to it as “AI”.

Consulting
Machine Learning
AI became unfashionable for quite some time, until it resurfaced in the 2000s as Machine Learning (ML). ML focussed more on algorithms (recipes given to a machine to do some useful work) than on philosophy and “blue sky” science. ML is more concerned with the particular configuration of the neural net that you are applying to a specific task than with, say, the philosophical implications of the Turing test.
Recent advances in algorithmics (e.g. backpropagation) and computing hardware have led to the possibility of calibrating and using large (deep) neural networks—Deep Learning (DL), and a resurgence of interest in ML.
As soon as ML became reasonably successful, it was rebranded back to AI.

Consulting
Linear Regression and Ensemble Methods
Linear regression is the workhorse of data science. It is a linear approach to modelling the relationship between a scalar response (or dependent variable) and one or more explanatory variables (or independent variables).
More recently, linear regression has been supplemented by ensemble methods, which use multiple learning algorithms to obtain better predictive performance than could be obtained from any of the constituent learning algorithms alone.
Ensemble methods include bootstrap aggregating (bagging), boosting, stacking, Bayesian model averaging, and more.
Consulting
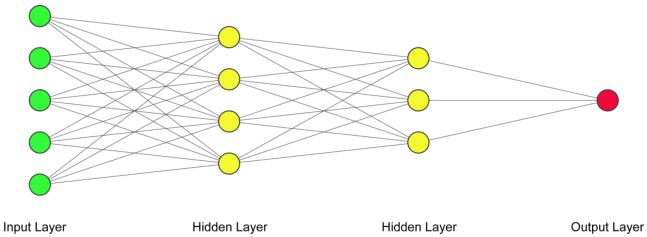
Neural Networks
Artificial neural networks (ANN) or connectionist systems are computing systems that are inspired by biological neural networks that constitute human brains. Such systems “learn” to perform tasks by considering examples, generally without being programmed with task-specific rules.
Advances in algorithmics (e.g. backpropagation) and hardware (e.g. availability of GPUs) have led to widespread and successful use of large (deep) neural networks (Deep Learning) across numerous application domains.
At Thalesians Ltd, we employ neural networks and deep learning to classify and forecast data from many diverse fields.

Consulting
Reinforcement Learning
Reinforcement learning (RL) is an area of machine learning concerned with how software agents ought to take actions in an environment in order to maximize the notion of cumulative reward.
Reinforcement learning is one of three basic machine learning paradigms, alongside supervised learning and unsupervised learning.
Reinforcement learning differs from supervised learning in not needing labelled input/output pairs to be presented, and in not needing sub-optimal actions to be explicitly corrected. Instead the focus is on finding a balance between exploration (of uncharted territory) and exploitation (of current knowledge).
The environment is typically stated in the form of a Markov decision process (MDP) because many reinforcement learning algorithms for this context use dynamic programming techniques. The main difference between the classical dynamic programming methods and reinforcement learning algorithms is that the latter do not assume knowledge of an exact mathematical model of the MDP and they target large MDPs where exact methods become infeasible.
Mathematics

Consulting
Stochastic Calculus
Stochastic calculus is a branch of mathematics that operates on stochastic processes. It allows a consistent theory of integration to be defined for integrals of stochastic processes with respect to stochastic processes. It is used to model systems that behave randomly.
The best-known stochastic process to which stochastic calculus is applied is the Wiener process (named in honour of Norbert Wiener), which is used for modelling Brownian motion as described by Louis Bachelier in 1900 and by Albert Einstein in 1905. The Wiener process is also used to model other physical diffusion processes in the space of particles subject to random forces.
Since the 1970s, the Wiener process has been widely applied in financial mathematics and economics to model the evolution in time of stock prices and bond interest rates. To this day it remains the lingua franca of quantitative finance.

Consulting
Frequentist and Bayesian Inference
Statistical inference is the process of using data analysis to draw conclusions about populations or scientific truths on the basis of a data sample. Inference can take many forms, but primary inferential aims will often be point estimation, to provide a “best guess” of an unknown parameter, and interval estimation, to produce ranges for unknown parameters that are supported by the data.
Under the frequentist approach, parameters and hypotheses are viewed as unknown but fixed (nonrandom) quantities, and consequently there is no possibility of making probability statements about these unknowns. As the name suggests, the frequentist approach is characterized by a frequency view of probability, and the behaviour of inferential procedures is evaluated under hypothetical repeated sampling of the data.
Under the Bayesian approach, a different line is taken. The parameters are regarded as random variables. As part of the model a prior distribution of the parameter is introduced. This is supposed to express a state of knowledge or ignorance about the parameters before the data are obtained (ex ante). Given the prior distribution, the probability model and the data, it is now possible to calculate the posterior (ex post) probability of the parameters given the data. From this distribution inferences about the parameters are made.
In modern era statistical inference is facilitated by probabilistic programming (PP) languages. The veteran BUGS/WinBUGS/OpenBUGS has been complemented by PyStan and PyMC3; and now PyMC4 is on the horizon.

Consulting
Stochastic Filtering, Markov Chain Monte Carlo, and Applications
Interest in the filtering problem dates back to the late 1930s–early 1940s. It was considered in Kolmogorov’s work on time series and Wiener’s on improving radar communication during WWII, which first appeared in 1942 as a classified memorandum nicknamed “The Yellow Peril”, so named after the colour of the paper on which it was printed.
Kalman extended this work to non-stationary processes. This work had military applications, notably the prediction of ballistic missile trajectories. Non-stationary processes were required to realistically model their launch and re-entry phases. Of course, non-stationary processes abound in other fields–even the standard Brownian motion of the basic Bachelier model in finance is non-stationary. Kalman’s fellow electrical engineers initially met his ideas with scepticism, so he ended up publishing in a mechanical engineering journal. In 1960, Kalman visited the NASA Ames Research Center, where Stanley F. Schmidt took interest in this work. This led to its adoption by the Apollo programme and other projects in aerospace and defence. The discrete-time version of the filter derived by Kalman is now known as the Kalman filter.
The general solutions are, however, infinite-dimensional and not easily applicable. In practice, numerical approximations are employed. Particle filters constitute a particularly important class of such approximations. These methods are sometimes referred to as sequential Monte Carlo (SMC), a term coined by Liu and Chen. The Monte Carlo techniques requisite for particle filtering date back to the work of Hammersley and Morton. Sequential importance sampling (SIS) dates back to the work of Mayne and Handschin. The important resampling step was added by Gordon, Salmond, and Smith, based on an idea by Rubin, to obtain the first sequential importance resampling (SIR) filter, which, in our experience, remains the most popular particle filtering algorithm used in practice.
Markov chain Monte Carlo (MCMC) takes its origin from the work of Nicholas Metropolis, Marshall N. Rosenbluth, Arianna W. Rosenbluth, Edward Teller, and Augusta H. Teller at Los Alamos on simulating a liquid in equilibrium with its gas phase. The discovery came when its authors realized that, instead of simulating the exact dynamics, they could simulate a certain Markov chain with the same equilibrium distribution.
Programming

Consulting
Python
Python is a programming language that was created by Guido van Rossum and first released in 1991. Its distinguishing characteristics are straightforwardness and readability, especially in comparison with other programming languages, such as C++ and Java. At the same time, Python is very expressive, powerful, and laconic, enabling programmers to express complex ideas in very little code.
Python is not only a language of choice for data science. It is frequently employed by web designers (for making websites), system administrators (for writing scripts and automation), hackers (also for writing scripts), and anyone who needs to process numeric and textual data in bulk.
Data scientists perform much of this programming inside the Jupyter environment. It is worth noting that Jupyter notebooks are not the only way to write Python code. You could launch the Python interpreter from the Anaconda Prompt and type in Python code closer to the metal. Or you could write your Python code in a text file, save it as “something.py” and end up with a standalone Python module or multiple such modules, forming a complex software product. This is something that we would do for a finished, polished solution in production. For research and prototyping, though, Jupyter notebooks are a perfect environment. (While Python is perfectly good for many production use cases, for others you may consider migrating to a language like C++, C#, or Java.)

Consulting
kdb+/q
q is a programming language for array processing, developed by Arthur Whitney on the basis of Kenneth E. Iverson’s APL. The kdb+ database built on top of q is a de facto standard technology for dealing with rapidly arriving, high-frequency, big data.
kdb+/q has taken the world of electronic, including algorithmic, trading by storm. It is used by numerous sell-side and buy-side institutions, including some of the most successful hedge funds and electronic market makers.
Beyond the world of electronic trading, kdb+/q is used in retail, gaming, manufacturing, telco, IoT, life sciences, utilities, and aerospace industries.
Consulting
C++
C++ is a general-purpose programming language created by Bjarne Stroustrup as an extension of the C programming language, or “C with Classes”. The language has expanded significantly over time, and modern C++ now has object-oriented, generic, and functional features in addition to facilities for low-level memory manipulation.
C++ was designed with a bias towards system programming and embedded, resource-constrained software and large systems, with performance, efficiency, and flexibility of use as its design highlights. C++ has also been found useful in many other contexts, with key strengths being software infrastructure and resource-constrained applications, including desktop applications, video games, servers (e.g. e-commerce, Web search, or SQL servers), and performance-critical applications (e.g. telephone switches or space probes).
In particular, in finance C++ is used extensively for building quantitative derivatives pricing systems and low-latency electronic trading systems.

Consulting
Low-latency C++
In the world of low-latency trading, you are never “fast enough”. Every nanosecond you can shave off your real-time flow will result in an increase in profitability.
This gives rise to a different way of programming with its own strict rules—the low-latency programming.
C++ is the language of choice for low-latency programming, although sometimes one employs special equipment, such as FPGAs.

Consulting
Java
Java is a class-based, object-oriented programming language that is designed to have as few implementation dependencies as possible. It is a general-purpose programming language intended to let application developers write once, run anywhere (WORA), meaning that compiled Java code can run on all platforms that support Java without the need for recompilation. Java applications are typically compiled to bytecode that can run on any Java virtual machine (JVM) regardless of the underlying computer architecture.
The syntax of Java is similar to C and C++, but has fewer low-level facilities than either of them. The Java runtime provides dynamic capabilities (such as reflection and runtime code modification) that are typically not available in traditional compiled languages.
As of 2019, Java was one of the most popular programming languages in use according to GitHub, particularly for client-server web applications, with a reported 9 million developers.

Consulting
C#
C# (pronounced see sharp, like the musical note, but weitten with the number sign) is a general-purpose, multi-paradigm programming language encompassing static typing, strong typing, lexically scoped, imperative, declarative, functional, generic, object-oriented (class-based), and component-oriented programming disciplines.
C# was developed around 2000 by Microsoft as part of its .NET initiative and later approved as an international standard by Ecma (ECMA-334) in 2002 and ISO (ISO/IEC 23270) in 2003. It was designed by Anders Hejlsberg, and its development team is currently led by Mads Torgersen, being one of the programming languages designed for the Common Language Infrastructure (CLI). The most recent version is 9.0, which was released in 2020 in .NET 5.0 and included in Visual Studio 2019 version 16.8.
Mono is a free and open-source project to develop a cross-platform compiler and runtime environment (i.e. a virtual machine) for the language.

Consulting
VBA
Visual Basic for Applications (VBA) is an implementation of Microsoft’s event-driven programming language Visual Basic 6, which was declared legacy in 2008, and is an associated integrated development environment (IDE).
As of 2020, VBA has held its position as “most dreaded” language for developers for 2 years according to Stack Overflow Developer Survey 2020. (The most dreaded language for 2018 was Visual Basic 6.)
Visual Basic for Applications enables building user-defined functions (UDFs), automating processes and accessing Windows API and other low-level functionality through dynamic-link libraries (DLLs). VBA is built into most Microsoft Office applications, including Office for Mac OS X (except version 2008), and other Microsoft applications, including Microsoft MapPoint and Microsoft Visio.
Hardware

Consulting
FPGAs
A field-programmable gate array (FPGA) is an integrated circuit designed to be configured by a customer or a designer after manufacturing—hence the term “field-programmable”.
The FPGA configuration is generally specified using a hardware description language (HDL), similar to that used for an application-specific integrated circuit (ASIC). Circuit diagrams were previously used to specify the configuration, but this is increasingly rare due to the advent of electronic design automation tools.
FPGAs contain an array of programmable logic blocks, and a hierarchy of “reconfigurable interconnects” that allow the blocks to be “wired together”, like many logic gates that can be interwired in different configurations. Logic blocks can be configured to perform complex combinatorial functions, or merely simple logic gates like AND and XOR. In most FPGAs, logic blocks also include memory elements, which may be simple flip-flops or more complete blocks of memory.
Many FPGAs can be reprogrammed to implement different logic functions, allowing flexible reconfigurable computing as performed in computer software.
FPGAs have a remarkable role in the embedded system development due to capability to start system software development simultaneously with hardware, enable system performance simulations at a very early phase of the development, and allow various system partitioning trials and iterations before final freezing of the system architecture.

Consulting
CUDA and General-Purpose GPU Computing
General-purpose computing on graphics processing units (GPGPU) is the use of a graphics processing unit (GPU), which typically handles computation only for computer graphics, to perform computation in applications traditionally handled by the central processing unit (CPU). The use of multiple video cards in one computer, or large numbers of graphics chips, further parallelizes the already parallel nature of graphics processing. In addition, even a single GPU-CPU framework provides advantages that multiple CPUs on their own do not offer due to the specialization in each chip.
Essentially, a GPGPU pipeline is a kind of parallel processing between one or more GPUs and CPUs that analyzes data as if it were in image or other graphic form. While GPUs operate at lower frequencies, they typically have many times the number of cores. Thus GPUs can process far more pictures and graphical data per second than a traditional CPU. Migrating data into graphical form and then using the GPU to scan and analyze it can create a large speedup.
GPGPU pipelines were developed at the beginning of the 21st century for graphics processing (e.g. for better shaders). These pipelines were found to fit scientific computing needs well, and have since been developed in this direction.

Consulting
Computer Architecture
Computer architecture is a set of rules and methods that describe the functionality, organization, and implementation of computer systems. Computer architecture involves instruction set architecture design, microarchitecture design, logic design, and implementation.
Business

Consulting
Electronic and High-Frequency Trading (HFT)
Electronification is the introduction of computerized systems into a process, such as trading.
Electronic trading is a method of trading relying on computer technology. Trading can be electronified to varying degrees, as evidenced by the following.
Algorithmic trading: (From early 90s.) The use of computer algorithms to make certain trading decisions and/or submit orders and/or manage those orders after submission. Algorithms may be used to calculate one or multiple of the price, timing, quantity, and other characteristics of orders. Not all algorithmic trading is automated as the actual placement of orders can still be done manually using the information produced by the algorithmic software.
Trading strategies (models): may refer to algorithms for pricing, quoting, order management, market making, electronic liquidity provision, statistical arbitrage, liquidity detection, latency arbitrage, etc.
Automated trading: (From late 90s.) A method of trading where computer software is used to fully automate order generation. Computers are linked to market data, which is fed into algorithms, and then automatically place orders in the market. Although the systems trade by themselves, they are controlled by both a risk manager and commands within the software.
High-frequency trading (HFT): (From 2000s.) “Employs extremely fast automated programs for generating, routing, cancelling, and executing orders in electronic markets.” [CK10] HFT occurs at a rate of action only computers can maintain. It is characterized by the sophisticated technology required to minimize latency, such as powerful computers with direct network connections to exchanges (including co-location).
[CK10] Jaksa Cvitanic and Andrei A. Kirilenko. High frequency traders and asset prices. SSRN Electronic Journal, 2010.

Consulting
Blockchain
A blockchain, originally block chain, is a growing list of records, called blocks, that are linked using cryptography. Each block contains a cryptographic hash of the previous block, a timestamp, and transaction data (generally represented as a Merkle tree).
By design, a blockchain is resistant to modification of its data. This is because once recorded, the data in any given block cannot be altered retroactively without alteration of all subsequent blocks.
For use as a distributed ledger, a blockchain is typically managed by a peer-to-peer network collectively adhering to a protocol for inter-node communication and validating new blocks. Although blockchain records are not unalterable, blockchains may be considered secure by design and exemplify a distributed computing system with high Byzantine fault tolerance.
Blockchain has been described as “an open, distributed ledger that can record transactions between two parties efficiently and in a verifiable and permanent way”.
The blockchain was invented by a person (or group of people) using the name Satoshi Nakamoto in 2008 to serve as the public transaction ledger of the cryptocurrency bitcoin. The identity of Satoshi Nakamoto remains unknown to date. The invention of the blockchain for bitcoin made it the first digital currency to solve the double-spending problem without the need of a trusted authority or central server.

Consulting
Cryptocurrencies
A cryptocurrency is a digital asset designed to work as a medium of exchange wherein individual coin ownership records are stored in a ledger existing in a form of computerized database using strong cryptography to secure transaction records, to control the creation of additional coins, and to verify the transfer of coin ownership.
It typically does not exist in physical form (like paper money) and is typically not issued by a central authority. Cryptocurrencies typically use decentralized control as opposed to centralized digital currency and central banking systems. When a cryptocurrency is minted or created prior to issuance or issued by a single issuer, it is generally considered centralized. When implemented with decentralized control, each cryptocurrency works through distributed ledger technology, typically a blockchain, that serves as a public financial transaction database.
Bitcoin, first released as open-source software in 2009, is the first decentralized cryptocurrency. Since the release of bitcoin, over 7,000 altcoins (alternative variants of bitcoin, or other cryptocurrencies) have been created.

Consulting
Foreign Exchange
The foreign exchange market (also known as forex, FX, or the currency market) is an over-the counter (OTC) global marketplace that determines the exchange rate for currencies around the world. Participants are able to buy, sell, exchange, and speculate on currencies. Foreign exchange markets are made up of banks, forex dealers, commercial companies, central banks, investment management firms, hedge funds, retail forex dealers, and investors.
A foreign currency derivative is a financial derivative whose payoff depends on the foreign exchange rates of two (or more) currencies. These instruments are commonly used for hedging foreign exchange risk or for currency speculation and arbitrage. Specific foreign exchange derivatives include: foreign currency forward contracts, foreign currency futures, foreign currency swaps, currency options, and foreign exchange binary options. These instruments are called derivatives because their value is derived from an underlying asset, a foreign currency. They are powerful tools for hedging (redistributing) foreign exchange risk, but at the same time, they are very risky instruments for inexperienced financial managers.
According to the Bank for International Settlements (BIS), which is owned by central banks, trading in foreign exchange markets averaged $6.6 trillion per day in April 2019.

Consulting
Credit
Credit risk, the risk that the promised cash flows from an asset will not be paid as promised, is a primary risk when investing in corporate bonds. Because corporate bonds are characterized by credit risk, investors demand a higher promised return on corporate bonds than on safer forms of investments, like U.S. Treasury bonds. Part of the higher return paid by corporations compensates investors for the expected losses due to default and part is a risk premium for bearing default risk. Since the late 1990s, corporate credit risk has traded not only through corporate debt, but also through derivative contracts known as credit default swaps (CDS). The exposure to corporate default through CDS is in many ways similar to a cash or direct exposure to corporate debt. There are, however, two important differences. First, since a CDS contract is between two counterparties, each is exposed to the counterparty risk of the other in addition to the corporate credit risk that is the purpose of trading the contract. This counterparty risk can be mitigated by the taking and posting of collateral. Second, the financing risks of a CDS position and a cash position are quite different. A counterparty in a CDS contract can maintain exposure to credit through the CDS maturity date by meeting any collateral calls. By contrast, maintaining a position in corporate bonds requires financing, either with capital, which can be expensive, or through repo markets, which is subject to significant liquidity risk.
A credit default swap index is a credit derivative used to hedge credit risk or to take a position on a basket of credit entities. Unlike a CDS, which is an over the counter credit derivative, a credit default swap index is a completely standardized credit security and may therefore be more liquid and trade at a smaller bid-offer spread. This means that it can be cheaper to hedge a portfolio of credit default swaps or bonds with a CDS index than it would be to buy many single name CDS to achieve a similar effect. Credit default swap indices are benchmarks for protecting investors owning bonds against default, and traders use them to speculate on changes in credit quality.

Consulting
Risk
An important general principle in finance is that there is a trade-off between risk and return when money is invested. The greater the risks taken, the higher the return that can be realized. In theory, shareholders should not be concerned with risks they can diversify away. The expected return they require should reflect only the amount of systematic (i.e., non-diversifiable) risk they are bearing.
Companies, although sensitive to the risk-return trade-off of their shareholders, are concerned about total risks when they do risk management. They do not ignore the unsystematic risk that their shareholders can diversity away. One valid reason for this is the existence of bankruptcy costs, which are the costs to shareholders resulting from the bankruptcy process itself.
For financial institutions such as banks and insurance companies there is another important reason: regulation. The regulators of financial institutions are primarily concerned with minimizing the probability that the institutions they regulate will fail. The probability of failure depends on the total risks being taken, not just the risks that cannot be diversified away by shareholders.
There are two broad risk management strategies open to a financial institution (or any other organization). One approach is to identify risks one by one and handle each one separately. This is sometimes referred to as risk decomposition. The other is to reduce risks by being well diversified. This is sometimes referred to as risk aggregation. Both approaches are typically used by financial institutions.

Consulting
Financial Regulation
Financial regulation subjects financial institutions to certain requirements, restrictions, and guidelines, aiming to maintain the stability and integrity of the financial system. Financial regulation has also influenced the structure of banking sectors by increasing the variety of financial products available.
The objectives of financial regulators are usually: market confidence–to maintain confidence in the financial system; financial stability–contributing to the protection and enhancement of stability of the financial system; consumer protection–securing the appropriate degree of protection for consumers.
Over the last few years, the financial services regulatory landscape has become more complex: Solvency II, FRTB, CVA, MiFID II, EMIR, PRIIP and other regulatory frameworks have been formulated.
Shipping

Shipping
The Shipping Industry
According to the International Chamber of Shipping, the international shipping industry carries around 90% of world trade. “Ships are technically sophisticated, high value assets (larger hi-tech vessels can cost over US $200 million to build), and the operation of merchant ships generates an estimated income of over half a trillion US dollars in freight rates.”
A successful application of AI to shipping technology is predicted to revolutionize this critical mode of transportation.

Shipping
Current Progress
According to Lloyd’s Maritime Agency, “AI is becoming increasingly important for the maritime industry. The rise of automation in the maritime supply chain along with the demand for more autonomous shipping has led to an increase in the demand for AI”. Among the most promising applications of AI within shipping they highlight predictive maintenance, intelligent scheduling, and real-time analytics.

AI in Shipping
Predictive Maintenance
Predictive maintenance (PdM) is “a prominent strategy for dealing with maintenance issues given the increasing need to minimise downtime and associated costs. One of the challenges with PdM is generating the so-called ‘health factors’, or quantitative indicators, of the status of a system and determining their relationship to operating costs and failure risk” [S15]. In shipping, PdM enables the scheduling of corrective maintenance before the vessels are on open waters, where repairs are significantly more challenging and costly. The AI-based system warns of looming failures in advance, thus helping the workers predict the optimal maintenance cycle of on-board machinery. In addition this enables the warehousing of spare parts in advance; reduced overhead costs; energy savings; and improve productivity.
[S15] Gian Antonio Susto et al. “Machine Learning for Predictive Maintenance: A Multiple Classifier Approach.” IEEE Transactions on Industrial Informatics, Volume 11, Issue 3, June 2015.

AI in Shipping
Intelligent Scheduling
Intelligent scheduling enables faster turnaround time of vessels and high-berth productivity—”paramount factors in container terminals for assuming competitive advantage in the shipping industry. […] Vessel scheduling/berthing system in a container terminal is regarded as a very complex dynamic application in today’s business world” [L15]. Recent advances in AI can dramatically simplify this process leading to significant improvements in efficiency and cost reductions.
[L15] Prasanna Lokuge, Damminda Alahakoon. “Improving the adaptability in automated vessel scheduling in container ports using intelligent software agents.” European Journal of Operational Research, 177(3):1985-2015.

AI in Shipping
Big Data and Real-Time Analytics
Big Data and real-time analytics are predicted to dramatically transform shipping: “A world where ships can ‘talk’. It may sound like a tagline for a science fiction movie but it’s not as far-fetched as it sounds — such ships could be coming to a sea near you within 10 years. […] Voyage data will be collated and used to enhance performance, productivity, and crucially, safety.”
Years of experience
0
Consultants
0
Industry-leading clients